|
I am a Ph.D. candidate in EE at UIUC, working with Prof. Paris Smaragdis. I like to do research at the intersection of signal processing and machine learning, applied to interesting problems in audio. Prior to this, I graduated from IIT Bombay with a B.Tech and M.Tech in Electrical Engineering. I've had the good fortune to work with and learn from some amazing research groups: AWS Audio Science, MTG Barcelona, DAP Lab and Honda Research. |

|
|
|
Accepted
|
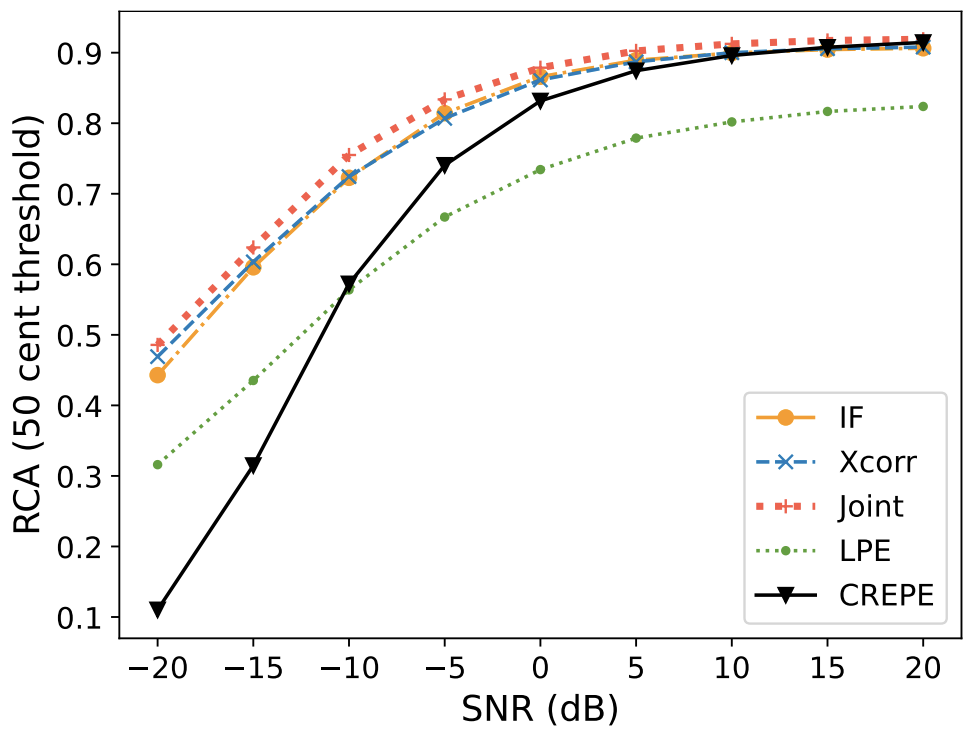
Krishna Subramani, Jean-Marc Valin, Jan Büethe, Paris Smaragdis, Mike Goodwin ICASSP 2024 Paper / Code / DOI We propose a noise robust DSP-assisted Neural Pitch Estimator that matches State-of-the-art CREPE with 3 orders of magnitude fewer parameters and a complexity of ~10MFLOPS (similar to conventional DSP based pitch estimators). We'll be presenting our work as an Oral Session at ICASSP. |
|
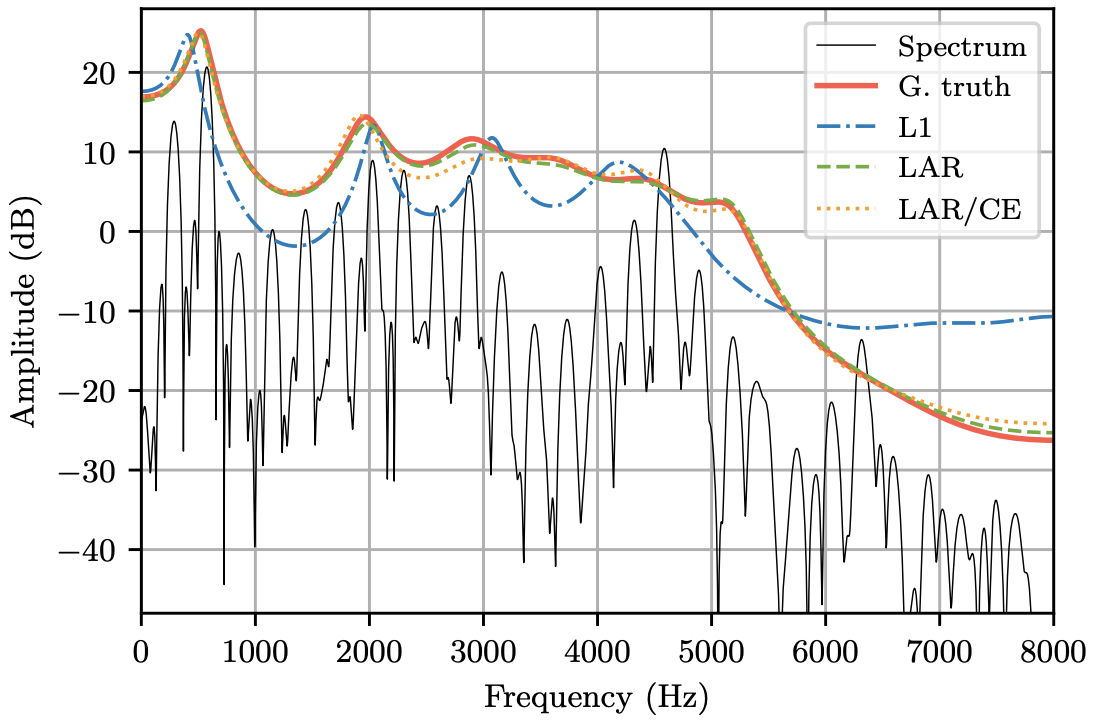
Krishna Subramani, Jean-Marc Valin, Umut Isik, Paris Smaragdis, Arvindh Krishnaswamy Interspeech 2022 Paper / Code / DOI We propose an end-to-end version of LPCNet that learns to infer the LP coefficients (without explicit analysis). Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features. We presented our work as a poster. |
|
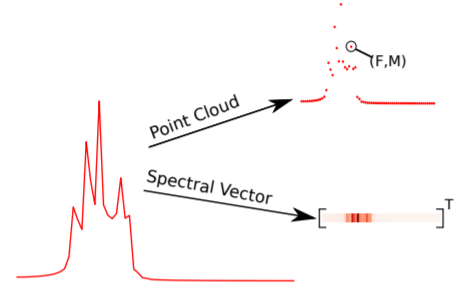
Krishna Subramani, Paris Smaragdis WASPAA 2021 (Best Paper Award) Paper / Code / DOI We introduce a novel way of processing audio signals by treating them as a collection of points in feature space, and we use point cloud machine learning models that give us invariance to the choice of representation parameters, such as DFT size or the sampling rate We presented our work as a virtual presentation. |
|
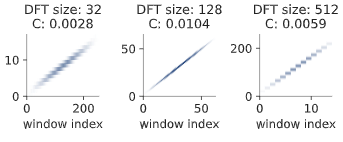
An Zhao, Krishna Subramani, Paris Smaragdis ICASSP 2021 Paper / Code / DOI We show an approach that allows us to obtain a gradient for STFT parameters with respect to arbitrary cost functions, and thus allows the use of gradient descent based optimization of quantities like the STFT window length, or the STFT hop size.
We presented our work as a virtual presentation. |
|
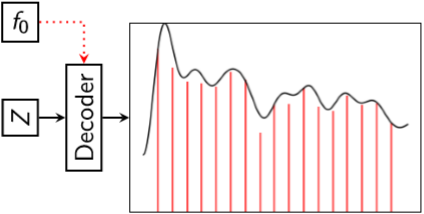
Krishna Subramani, Preeti Rao Alexandre D'Hooge ICASSP 2020 Paper / Code / Audio Examples / DOI We present VaPar Synth - a Variational Parametric Synthesizer for instrument note synthesis, which utilizes a conditional variational autoencoder trained on a source-filter inspired parametric representation. We presented our work as a virtual presentation. |
|
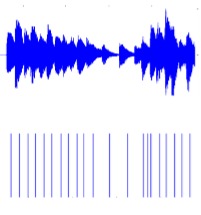
Krishna Subramani, Srivatsan Sridhar, Rohit M A, Preeti Rao National Conference on Communications 2018 Paper / DOI Propose the use of energy-based weighting of multi-band onset detection functions and the use of a new criterion for adapting the final peak-picking threshold to improve detection of soft onsets in the vicinity of loud notes. Also propose a grouping algorithm to reduce the detection of spurious onsets. We presented our work as an oral presentation |
Preprints
|
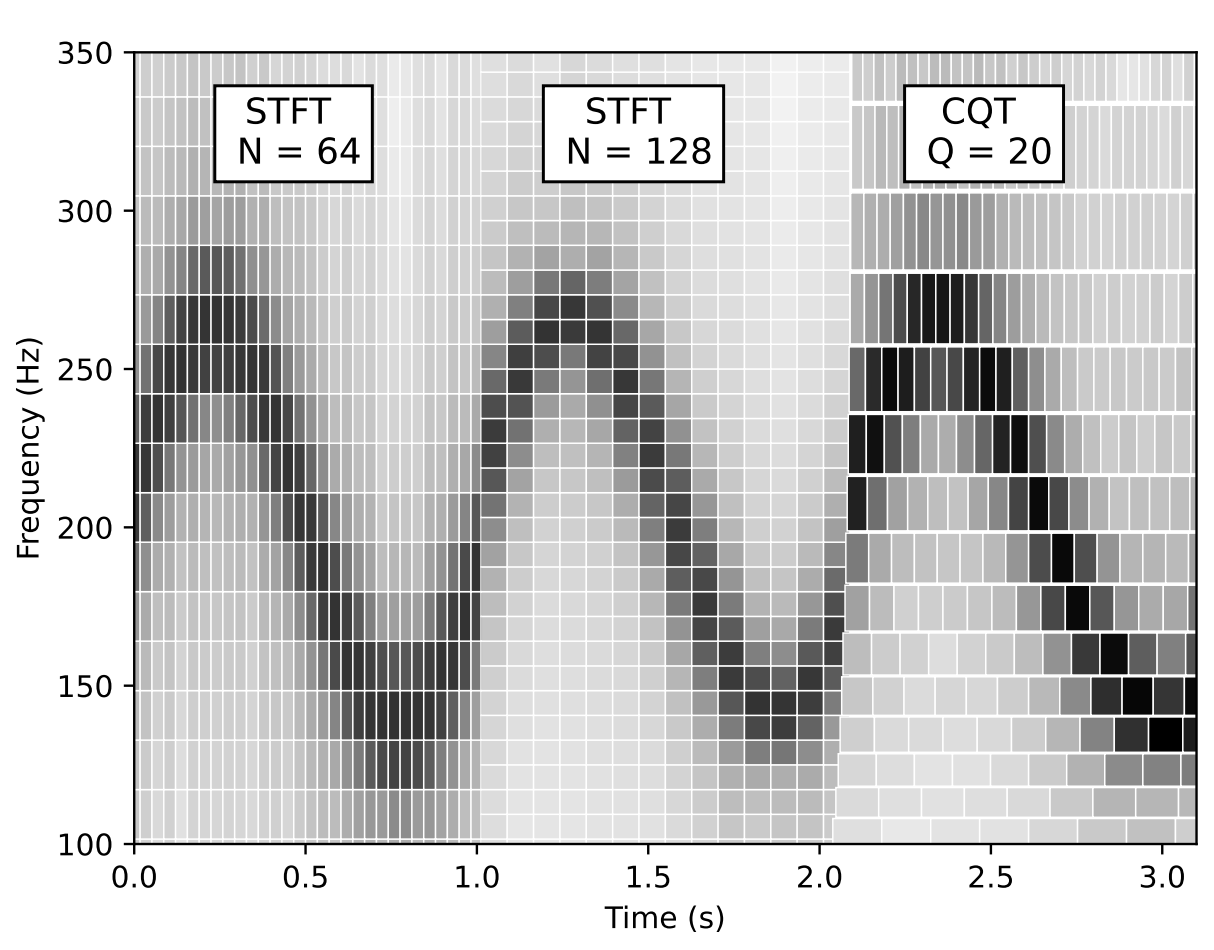
Krishna Subramani, Paris Smaragdis, Takuya Higuchi, Mehrez Souden arXiv / Code We propose Implicit-Neural NMF, a framework that describes NMF in terms of continuous functions instead of fixed vectors. This allows us to extend NMF to a wider variety of signals that need not be regularly sampled, like the Constant-Q transform, Sinusoidal models etc. |
|
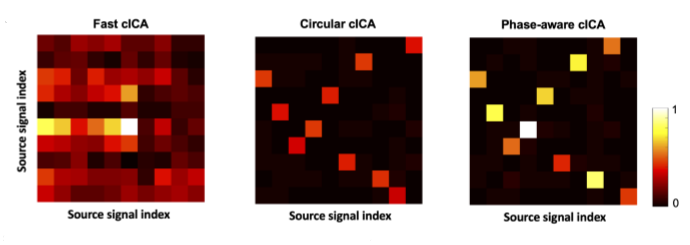
HaDi Maboudi, Krishna Subramani, Hamid Soltanian-Zadeh, Shun-ichi Amari, Hideaki Shimazaki bioRxiv We introduce a generative model for phase in visual systems, and propose a complex domain based maximum likelihood estimation procedure for parameter estimation. We derive analytical gradient expressions for maximum likelihood estimation using Wirtinger Calculus (detailed in our supplementary material) I presented the initial part of this work as an oral presentation at Honda Research Institute, Saitama, Japan |
|
Krishna Subramani, Preeti Rao arXiv / Code / Audio Examples We investigate a parametric model for violin tones, in particular the generative modeling of the residual bow noise to make for more natural tone quality. To aid in our analysis, we record a dataset of Carnatic Violin Recordings. We also present a simple GUI (inspired from SMS-Tools!) for researchers to play around with, where they can load pre-trained network weights and reconstruct/generate user input audio files. |
|
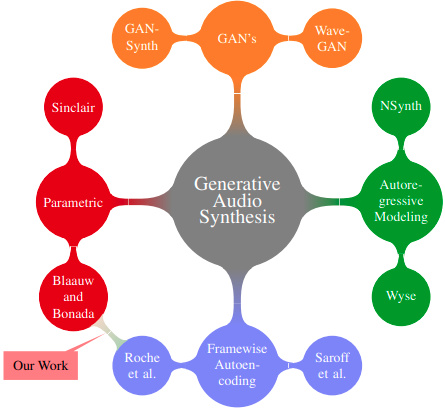
Thesis / Presentation / BibTeX My Master's Thesis on generative audio synthesis, where we introduce a Variational Parametric Framework for the synthesis of instrumental tones. I received the Undergraduate Research Award (URA03) from IIT Bombay for my thesis as recognition of truly exceptional work and research contributions. |
|
The Master Yoda to us Padawans. |